新しいことについて学びたいんだけれど、まだ単語レベルの知識しかない。
書店に行ってみるとたくさん本があって、どれを選んで読んでいいかわからない。
仕方なくAmazonのレーティングとレビューを見て買ってみたものの、何か合わない。
そんな経験をしたことはないでしょうか。
わたしは超あります。でもそれなりのお金を払って買った本だから処分することもできず、積読。。。
本が「合わない」理由
買ってみた本が「合わない」理由はいくつかあります。
レベルが合わない
たとえば技術書にはそれぞれ、想定する読者がいます。気の利いた本なら、本の最初の部分に、その「想定する読者」や「前提知識」まで書いてくれています。これに合う本を読むことが大切です。
目的が合わない
技術の全体を俯瞰したい人と、その中の特定のことについて深掘りしたい人では、必要な本は違ってくるでしょう。
その人の目的と、本の意図が合っていないと、不幸なことになります。
デザインやノリが合わない
ぶっちゃけわたしは、表紙のジャケ買い、フォントの大きさと行間の広さ、「せっかくだからシリーズで揃えたい」みたいな、まったく本質的でない理由で技術書を選んで、1と2の理由で自分に合わず、失敗することが多いです。 でもそれくらい、見た目とか論調って大事なんですよ・・・それが合わないと買う気がしない。
以上のような理由で本を積んでしまうと、自分だけでなく、積まれてしまった本にとっても不幸です。
図書館貯蔵本濫読メソッド
そんな時にわたしが採用しているケチケチ勉強法・「図書館貯蔵本濫読メソッド」を紹介します。
やり方は単純。名前を付けるまでもない。
- そのテーマの本をかたっぱしから図書館で借りる。
- 難易度と、できればもう1軸くらいを見つけて、それぞれの本をマッピングしてみる。
- 自分の目的とレベルに沿って、勉強に使う本を決める。
- 選んだ本を買って勉強する。
これで、勉強を始めるコストが限りなく低くなります。
1. 図書館で借りまくる
図書館のWebサイトの検索は充実しているし、最寄りの図書館になくても市内であれば取り寄せしてくれたりもします。
「ソフトウェアテスト」なんて比較的マイナーな分野でも、意外に蔵書があったりします。わたしの地元だと6冊もありました。
当然ですが、図書館で扱う技術書のカバー率は高くなく、できるだけ「広く読まれる」本が多くなる傾向があります。
でも、右も左もわからないモノを学ぶのですから、その手の本で最初は十分なのです。
たとえばAWS(Amazon Web Services)について、すぐに借りられる本を4冊読んでみました。
なおこの時点での「読む」の目的は、深い理解ではなく、本の傾向をつかむことです。合わなければ読むのをやめて返せばいいです。
- Amazon Web Services入門 ― 企業システムへの導入障壁を徹底解消
- Amazon Web Services 徹底活用ガイド (日経BPムック)
- AWSクラウドの基本と仕組み
- Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版
- Amazon Web Servicesインフラサービス活用大全 システム構築/自動化、データストア、高信頼化 (impress top gear) *1
2. 本をマッピングする
複数の本を読んでいくと、同じテーマを扱っていても、それぞれ立ち位置が微妙に異なることに気づきます。
AWSの本の場合だと、分類の軸として、「難易度」に加え、「ビジネス寄りか、技術寄りか」という軸があると感じました。
難易度というのは絶対的な尺度ではなく、自分が読んでみて平易と感じたか難解と感じたかという主観です。人によってもっている知識が違うので、他の人にとっては相対値ですね。
ビジネス⇔技術 という表現は妥当かわかりませんが、たとえば「オンプレの自社システムをパブリッククラウドの移行したいのだけれど、AWSのビジネス・課金・契約はどういうものなのかを知りたい人」*2と、「AWSにアカウントを作ってとりあえず触ってみたい人」*3では、必要とする本がまったく違います。
上の5冊をわたしの主観でマッピングすると、以下のようになりました。
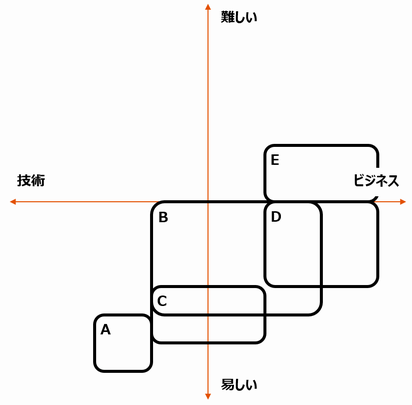
図書館の本なので、「易しい」寄りの本が多いことがわかりますね。
当然ですが、このマトリクスのここにあるからいい本だ・悪い本だ、ということを意味していません。
3. 本を決める
わたしのレベルと目的を踏まえると、まずCを読んで全体を理解し、Dで手を動かしてみる、というのがよさそうに思えます。勉強の進め方は以下のようになります。
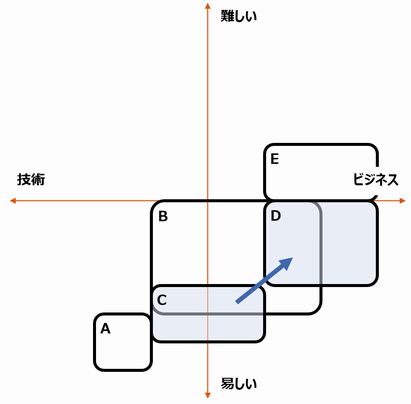
せっかくなので、CとDがどんな本か、紹介してみましょう。

↑この本は、AWSの主要サービスについて、技術的な解説も含めて概観的に網羅しています。全体を知りたい、忘れたときにぱっと概要を思い出したいという目的に合いそうです。
主要なサービス、VPC・S3・EC2・Lambdaなどについては、やや詳しく「このように使える」といったところまで説明されています。詳しい仕様や設定方法は対象外です。

↑こちらは、AWSを実際に使ってWordPressのサービスを立ち上げるところまでを案内しています。そのために必要なAWSサービスに解説を絞っている代わりに、スクリーンショットレベルで手順を詳説するものです。
また、AWS以前に必要な知識、たとえばネットワークなら、IPアドレス・DNS・ルーティングといった技術の基本的な解説もカバーしているため、「AWS以前の勉強から必要だった・・・」とならないですむようになっています。スクショ&基本技術解説となると分厚くなりそうなものなのですが、200ページちょっとで収めているのがすごい。
4. 勉強する!
するだけです。簡単ですね?*4
図書館で借りられる本の特徴と注意点
特徴
- 書店では手に入りづらいムック(日経BPがよく出してる)を入手しやすい。
- 資格関連の本はあまりないかも。たとえばAWSだと、認定関連の本が少なかったです。
- 古い本も混じってきます。たとえばAWSについて調べるのに、5年前の本だときっと古い情報も多いでしょう。
注意点
- いっぺんに借りると、同じテーマを勉強したい人に迷惑なので、避けましょう。
- 技術書に限らず、人気のある本、良い本は貸出中の可能性も高いので、「そうでない本」が手元に集まりやすいという欠点があります。
- 「イイ!」と思った本は、著者の方に感謝し、お金を出して買いましょう。
- いや、公式ドキュメント読めよ!というのはその通りなので、次のステップではそうしましょう・・・。
レビューコメント
Amazonのレビューは参考になりますが、レビュアがその「想定する読者」に合っていたのかどうかまではわかりません。
たとえば「初歩的なことしか書いておらず、実務ではまったく使えない」というレビュー。レベル5の人向けに書いた本をレベル10の人が読めば、そうなるでしょう。でもレベル5の人には必要十分かもしれません。
このようなレビューコメントを見てしまうと、買うのにちょっと躊躇してしまいますよね。
なのでAmazonの評価はあまり気にしない方がいいですが、「事実誤認が多い」とか「内容が古い」、この辺は多少気にした方がよさそうです。
まとめ
図書館を利用して合う本を見つけ、合う本には金を払い、合う本で勉強しましょう。
 "YDS Library" by Chris and Amy Stroup is licensed under CC BY-NC 2.0
"YDS Library" by Chris and Amy Stroup is licensed under CC BY-NC 2.0![]()
![]()
![]()