『テスト管理を語る夕べ』というイベントで、お話をさせていただきました。
主催のみっきーさん、インフラ整えてくださってしんすくさんとなそさん、twitter実況してくれた書記のぱいんさんとブロッコリーさん、←どんなメンツなんだ?
そしてこんなマニアック目なテーマの勉強会に金曜夜を使ってくれた奇特な参加者のみなさんに感謝します。
kataruyube.connpass.com togetter.com
「テスト管理」というと対象範囲が広く、たとえば「テストの進捗に遅延が発生した際に、どのように解決していくのか!」といった、かっこいい感じの「テスト管理」もあるのですが、今回の発表は地味な「テストケースの持つべき情報・構造」に関するものです。
Excelによる2次元表でのテストケース&テスト実行管理というのがもっとも「わかりやすい」ものですが、その扱いづらさ、限界、破綻を感じるは少なくないでしょう。
たとえば2回同じテストを行い、その結果がExcelの1行に「pass/fail」と記載されているのを見たことがありませんか。こんな些細なことでも以下のような問題があります。
- 1つの行に複数の結果が書かれており、集計が困難になる。
- 2回のテストが、どのプロダクトバージョンで行われたか追跡できない。
- 同じプロダクトバージョンで2回目で合格したとしたら、テストケースの方を修正した可能性があるが、それも追跡できない。
場合によってはそこから、いわゆる「テスト管理ツール」の検討に進む組織もあるでしょう。しかしそれもうまくいくとは限りません。
テスト管理ツールが提案するテスト管理・表現方法と、自組織の考え方が合わない。手動テストと自動テストをうまくシームレスに扱えない。導入のためのイニシャルコスト(検討、ツール比較、パイロット導入、ルール作成、トレーニング、・・・)が払えないなど。
幸いわたしは、仕事の一部にテスト管理ツールを導入できていますが、それもどうも、ニーズを完全に満たすものではない。
そんな中で、そもそもテストケースというものはどのような「カタチ」をしているべきなのだろう。また他の成果物とどのような関係を持つべきなのだろう。ということをあらためて考え始めました。ざくっとまとめてTwitterに投げたのが、以下です。
@yoshitake_1201 @MAQ69 @s_banban 月初に話したテスト管理のやつ、昨日の夜中に書き殴ったので御レビューお願いしますw 僕が触ったことのあるテスト管理ツールはSquashTMとTestLinkだけです。
— Kazu SUZUKI (@kz_suzuki) September 17, 2018
※パワポテンプレは無視して…。 pic.twitter.com/yVLIzLY1l2
これに対し有益なコメントをたくさんいただけたので、一人で盛り上がって2次検討した結果が、以下の表とER図です。ER図は記法がいい加減なので「エセ」ですが。
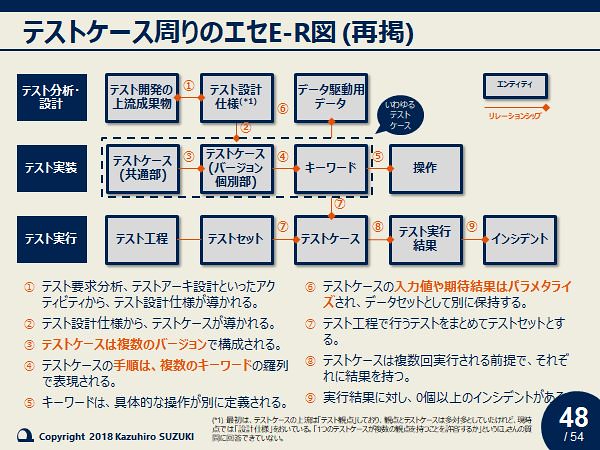
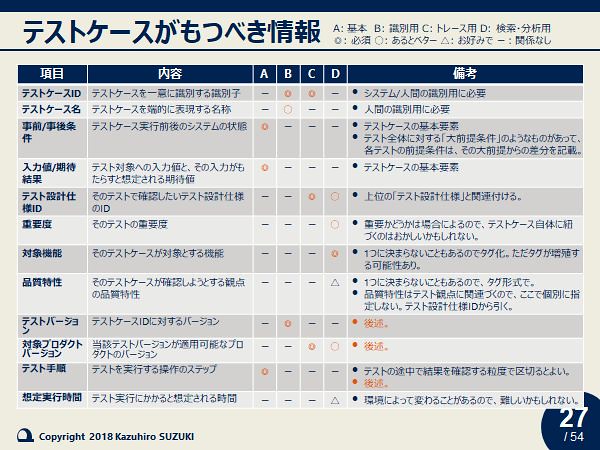
今回はこの2つを中心に、
- テストケースのバージョンとは
- テストケースのパラメタライズとは
- キーワード駆動テストとは
などについて自分の考えを説明しました。
後半はパトスがほとばしり過ぎて謎の早口おじさんになっていた気がしますが、少なくとも一部の方には興味を持っていただけたようで、ほっとしました。
さて、以下に資料を公開していますが、当日多くのツッコミを受けたことからもわかるとおり、ドラフトに過ぎない資料です。
今回いただいたご質問・ご指摘を踏まえてもう少しブラッシュアップしようと思っています。また、これもう少し進めたいねというご意見があれば、第2回目もやりたいなー(わたしはあまりしゃべらない立場で)とも思います。
www.slideshare.net
この記事は「前編」です。「後編」では、いただいたコメントに対し、現時点での回答を試みます。



