アジャイル開発において、プロダクトや組織の現状を把握するのに役立つメトリクスを知りたいと思い、「agile kpi」などでググって上位のサイトを読むという丁寧なサーベイを敢行。20個くらい読んでいくとだいぶネタも尽きてきたので、整理してみました*1。参考にしたサイトについては、記事の最後に載せておきます。
なお以下では、アジャイル開発とスクラム開発をほぼ同じ意味で使っていますが、怒らないでいただきたいですね。
メトリクスとKPI
メトリクス(metric / metrics*2)とKPIはごちゃごちゃに使われがちです。こちらの資料では、以下のように説明しています。
www.slideshare.net
- メトリック: プロセス・プロダクト・チームの定量的な評価・制御・改善のための物差し、またはその組み合わせ
- KPI: 戦略的な目標に強く紐づけられた、最低1つの期限付き目標をもったメトリック
KPIの設定方法として、有名な「SMART」や「INVEST」といった基準に言及しています。
では、各サイトで言及されているメトリクスについて紹介していきます。
ざっくりと、「開発能力」「進捗」「プロセス」「品質」に区分していますが、複数の区分にまたがるものもあります。
開発能力
チームの開発能力を測ることのできるメトリクスは、以下のものです。
- ベロシティ
- サイクルタイム
- 平均欠陥修復時間 (MTTR)
ベロシティ
スプリント内で完了できた仕事の量。
仕事の量は、見積もり規模であったり、ストーリーポイントであったり、チームによってさまざまでしょう。
ベロシティを測定する目的の一つは、自分たちが一定期間に開発できる量を知り、見積もりの精度を上げることです。スプリントを重ねていくと、ベロシティが安定していくことが期待できます。低下傾向にあるようなら、開発プロセスに非効率な部分があるとか、コードの保守性が悪化しているといった問題の兆候かもしれません。
サイクルタイム
タスクの消化にかかる平均時間。要件の特定からリリースまでの「リードタイム」(TTM)の対となる概念という扱いです。
具体的には、タスクが仕掛中(doing)になっている時間を測っています。タスクが適切に分割されていれば、サイクルタイムは一定になるはずで、開発能力や開発プロセスの安定を見ることができるという理屈です。
このメトリクスは今回の調べる中で初めて知ったのですが、扱っているサイトは多く、一般的なもののようです。
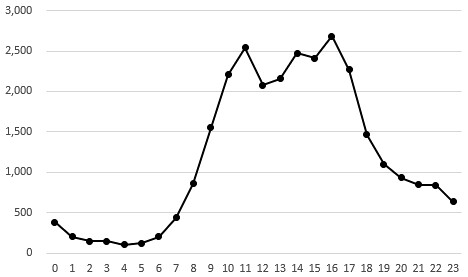
下の図は、Main Agile Software Development Metrics and KPIsから引用したものです。平均、移動平均、標準偏差と、サイクルタイムを1つの図に表現しています。

サイクルタイムが短いということは、開発の能力が高いというだけでなく、品質問題による手戻りが少ない、作業の待ち時間が短い、コンテキストスイッチが少ないなど、品質や開発プロセスの良さによるものかもしれません。逆もしかりで、サイクルタイムの悪化は、品質やプロセスに何か問題のある兆候と考えられます。
サイクルタイムは「安定して」「徐々に短くなっている」ことを目指すことになります。実装と欠陥改修のタスクを分けて計測しているケースもあるようです。
平均欠陥修復時間 (MTTR)
欠陥修復までの平均時間。欠陥数 / 改修のためのコーディング時間 で算出します。
MTTR(Mean Time To Repair、平均修理時間)は、コンピュータシステムの保守性を表す指標として有名です。これを開発チームの効率を測るのに使ったものです。
ここでは「開発能力」にカテゴライズしていますが、問題発見から原因特定・改修・テストまでのプロセスが円滑であるとか、原因の特定や改修が容易な、保守性の高いプロダクトであるといったことも考えられます。
この指標も、たとえば「バージョンを重ねるごとにMTTRが低下しているのは、技術的負債が増加しているためでは」「品質が悪すぎるので、新規開発を止めて改修に専念すべきなのでは」というように、問題の兆候と捉えたり対策を打ったりするのに役立ちそうです。
進捗
開発の進捗を測ることのできるメトリクスは、以下のものです。
- バーンダウンチャート
- テスト進捗率
バーンダウンチャート
進捗をみるうえで代表的なのが、タスクの消化具合を可視化した、このバーンダウンチャートでしょうか(バーンダウンチャート自体はメトリクスではありませんが・・・)。残日数と仕事量から算出した理想線と実際の線を比較することで、進捗状況の把握や、完了見込みの推定を行います。スプリント単位でも、バージョン単位でも用途があります。
ポイントとして、「開発の途中での総作業量の増加」を見える化することも大事です。ある1日に10SPの仕事を消化した一方で、何らかの理由で10SPの仕事が追加されてしまった場合に、単に「グラフが下がらない」と見えるだけだと困ります。「消化した分、下がる線」(傾きがベロシティに相当)と、「追加された分、上がる線」(各時点での全作業量に相当)を見られるようにしておくべきでしょう。
他の表現方法として、「追加された分を棒グラフの負の側に出す」というものもありました。こちらの方が直観的にわかりやすいかもしれません。
下の図は、サイクルタイムと同様、Main Agile Software Development Metrics and KPIsから引用しています。

なおアジャイル開発において、1つの開発バージョンの中でスコープの変更が起こることは必然です。一方スプリントの中で頻繁にスコープクリープが発生するのはよくないことでしょう。要件の受け入れやタスクの工数見積もりに問題がないかの確認が必要です。
テスト進捗率
テスト全数に対し、完了しているテストの数で、時間推移を見ます。
チケット管理と一元化されているか、テスト管理ツールで別管理するかはチームによります。
プロセス
プロセスの良しあしを測ることのできるメトリクスは、以下のものです。
- タスクのステータス分布
- リリースオーバーヘッド
- フロー効率性
- 予見性
タスクのステータス分布
タスクのステータス(たとえば todo、doing、doneの3種類)を色分けして積み上げたもの(累積フローチャート、累積フロー図)です。doingの層の横幅が、上述のサイクルタイムに相当します。また、Main Agile Software Development Metrics and KPIsから引用しています。

健全な状況では時間ともにdoneの割合が増えていくことが期待されれます。
doingの割合が増加傾向にあれば、doneに進められないようなプロセス上の問題や、ブロックしているバックログがあるのかもしれません。あるいは、WIP(Work in Progress)タスクが多すぎてコンテキストスイッチが多発し、開発効率が落ちているかもしれません。チームメンバーのWIP数と流出欠陥には相関があるという調査(PDF)もあります。
これもやはり、問題を早期に発見するためのツールといえるでしょう。
タスクの種類が、実装なのかバグの改修なのか、はたまた環境構築なのかによってグラフを分けてみれば、新しい知見があるかもしれません。インシデントレポートはどんどん増えているのに、一向にdoingにならない、とか・・・。
リリースオーバーヘッド
リリースのためにかかる時間やコストを表します。
短い周期で定期的にリリースするのであれば、そのための時間とコストを小さくする必要があります。RC(Release Candidate)のテストやデプロイ前の確認フェーズでの時間やコストを計測し、ボトルネックを見つけることで、プロセスの効率化を図ります。
フロー効率性
実働時間と待ち時間の割合を示します。
他のタスクの完了を前提とするようなタスクが増えてくると、前提タスクの完了を待つ時間も長くなってしまします。そのような非効率を可視化し、プロセスの劣化やボトルネットを検出することができます。
このフロー効率性と、対をなす概念であるリソース効率性については、以下のページがとてもわかりやすいです。
予見性
各メトリクスにおける計画と実績の乖離をみるという、メタ的なメトリクスです。
メトリクスについていろいろな記事を読んでいると、「開発能力が高い」ということと同じくらい、「安定している」ことが求められていることに気づきます。プロセスが安定していて、見積もりの精度が高い。これをpredictability(予見可能性)と呼んでいます。
予定との差の大きさや、実績値の標準偏差を測定し、ばらつきが少なくなるように改善をすることになります。ばらつきが少なければ、見込むバッファも小さくてすむようになります。
品質
もともとこれが知りたくて調査を始めたのでした。
品質の良しあしを測ることのできるメトリクスは、以下のものです。
- コードカバレッジ
- コードの複雑度
- コードチャーン (code churn)
- 欠陥密度
- 欠陥の出方
- DDP (Defect Detection Percentage、欠陥検出率)
- 平均欠陥検出時間 (MTTD)
- テストの成功率
- ビルドの成功率
コードカバレッジ
JSTQB用語集(PDF)での定義は、以下の通り。
テストスイートが、ソフトウェアのどの部分を実行(カバー)し、どの部分が未実行かを判定する分析手法。たとえば、ステートメントカバレッジ、デシジョンカバレッジ、条件カバレッジ。
品質の十分条件というより、必要条件的に使われることが多いと思います。
ステートメントカバレッジ・デシジョンカバレッジ100%を目指す組織もあれば、『知識ゼロから学ぶソフトウェアテスト』では「一般の商用ソフトウェアなら60~90%で十分」としています。(60~90は幅広いですけど・・・)

カバレッジの種類はいくつかあるので、意味を理解しておく必要があります。このブログでは以下で紹介しています。
コードの複雑度
ソースコードがどれだけ複雑かを定量化したものです。
コードが複雑であれば、欠陥を埋め込みやすく、テストも複雑になるため、プロダクトの品質の悪化につながるでしょう。 また、同じ理由で改修も難しくなってしまうので、保守性も悪くなり、長期的な品質に影響します。複雑度は、欠陥を埋め込みやすいリスクの高いコードを特定し、コードレビューやリファクタリングの優先順位付けに利用することができます。
複雑度の例としては、ネストの深さやクラスの結合度、McCabeのCyclomatic複雑度、Halsteadの複雑度などがあります。ただ、人間と機械では複雑さに対する感覚が異なるので注意が必要です。先日の機械学習のイベントでも、富士通アプリケーションズさんのお話で、「コード解析では複雑と判定されなくても、人間にとっては読みづらいコードを学習させる」というお話がありました。
www.kzsuzuki.com またこれ以外のコードメトリクスとして、コードクローンやセキュリティ脆弱性など、主にツールを使って検出するものもありますね。
コードチャーン (code churn)
どのくらいのコードが追加・削除・変更されたかという情報から、開発ステージごとのコードの安定性を見る指標です。
Qiitaの @hirokidaichi さんの記事では、以下のように説明されています。
複数人で複数回にわたって編集されたファイルは複数の目的でコードが編集されている訳ですから、「単一責務原則」を違反している可能性が高く、潜在的にバグを内在していそうだということです。
増加傾向(コードの修正が頻繁になっている)であれば、テストが不足している可能性があります。また、リリース直前に複数の人間による多くのコミットがあれば、そのコードが安定しているかを調査する必要があるでしょう。
欠陥密度
開発規模(SLOC、FP、ストーリーポイントなど)あたりの欠陥の数です。WFでも何かと議論になりがちなメトリクスですね。
たとえばSLOC(source lines of code)を分母とするケースでのわかりやすい欠点としては、実装の難しさやコードの複雑さが考慮されないというものがあります。「大きな組織で1つの基準を設け、全プロジェクトでその基準を参照する」よりは、1つのプロダクトの中でトレンドを見る方がよさそうです。SPを分母にする場合は、他チームとの比較がそもそもできないでしょう。
ベロシティなどと同様、安定していれば見積もりにも使えるようになりますし、何らかの異常を検知することもできます。
欠陥の出方
アジャイル開発に限った話ではありませんが、欠陥をいろいろな観点で分析することは重要です。たとえば、機能・ストーリーでの分類、重要度での分類、品質特性(機能性、性能、ユーザビリティ、保守性、・・・)での分類、オープン/クローズの時間推移など。
ただ、分類と数字だけで判断するべきではなく、傾向を見つけたらそのエリアのバグ票の中身にまで突っ込んでいくことが必要になるでしょう。
アジャイル開発においてもシフトレフトアプローチは有効で、早期に見つけるほど改修コストは下がります。
DDP (Defect Detection Percentage、欠陥検出率)
プロダクトの全欠陥のうち、開発の中で摘出できたものの割合です。DDPが高いほど、開発の中でしっかり欠陥を刈り取れているということになります。
ウォーターフォールの文脈ですが、『システムテスト自動化 標準ガイド』では、「開発中」と「リリース後」の二分だけでなく、開発中の各テストフェーズでのDDPを算出する話が出てきます。たとえば、結合テスト(欠陥80件)→システムテスト(欠陥15件)→ユーザ受け入れテスト(欠陥3件)→リリース(欠陥2件) とすると、以下のように計算できます。
- テストのDDP = (80+15+3) / (80+15+3+2) = 98.0 %
- システムテスト完了時点での結合テストのDDP = 80 / (80+15) = 84.2 %
")
たとえばテスト工程をスプリントで読みかえて・・・ということも考えてみますが、適切な読み替えではなさそうでもあり。アジャイル開発の文脈で、DDPをうまく使っている例があれば知りたいです。
リリース後の欠陥という観点では、fabric.ioのようなサービスを利用しての、モバイルアプリクラッシュステータスの監視に言及しているサイトもありました。
平均欠陥検出時間 (MTTD)
MTTRがはシステムの保守性を表していたのに対し、MTBF(Mean Time Between Failure)はシステムの信頼性を表現するメトリクスです。
MTTDはそのアナロジーで、「テスターが次の欠陥にぶつかるまでの平均時間」になります。これはプロダクトの品質・信頼性に依存しますが、テストの質やテストエンジニアの能力にも依ります。
テストの成功率
実行したテストの成功の割合です。時系列でみると、向上していくのが理想です。終盤で伸び悩んでいる場合は、欠陥をクローズできていないなどの問題があり、危険の兆候です。
もちろん、テスト側に問題があることもあります。テストの期待値が誤っている、テストが壊れている、など。
ビルドの成功率
「最後のビルド失敗からの日数」「ビルド連続失敗回数」などで表現するもので、ビルドプロセスが安定しているかの指標になります。
システムテストに入る前のコードに問題がないか、チームのホワイトボックステストのやり方に問題ないかといった観点での改善につながります。
メトリクスの扱い方
さて、アジャイルに限ったことではありませんが、メトリクスには以下のような注意点があります。
- 報告される側は、個人の評価に使わない。
- 報告する側は、取り繕うためにデータを歪めない。
- 収集に手間がかかりすぎるものは避ける。できるだけ自動で取得・集計・表示できるように。
またこちらのページでは、短期と長期に分けて、ダッシュボードで見える化することを勧めています。
メトリクスの例は、以下の通りです。
- 短期 ビルドの成功率、自動テストの成功率、、バーンダウンチャート、追加された致命的バグ、未解決な致命的バグ、・・・
- 長期 テストの失敗率、テストの数、ベロシティ、種類別バグ、・・・
www.slideshare.net
おわりに
一通り紹介してみましたが、いかがでしょうか。
もともとの動機が「品質に関わるメトリクス」だったので、偏りがあると思います。進捗を表すメトリクスが2つしかないし、コストに関しては1つも書いていません。実は、EVM(Earned Value Management)をアジャイルに適用する試みについての記事も読んだのですが、割愛しています。
みなさんのチームで使われているナイスなメトリクスも教えていただきたいです。特に品質!
追記
Twitterなどで寄せていただいた有益なサイトへのリンクです。
https://www.slideshare.net/oota_ken/agile-mericswww.slideshare.net
辰巳さんからご紹介いただいた、SHIFTの太田さんのスライド。よっぽどちゃんとまとまっていました・・・。
www.slideshare.net
LINEの伊藤宏幸さんの資料(楽天在籍当時)。Twitterで言及していたところ、ご本人に紹介いただきました。ありがとうございます。
CFD、スループット、サイクルタイム、リードタイムなどに言及があります。
www.slideshare.net
こちらも伊藤さんの資料。実際に現場で適用した内容なので、説得力が違いますね。
また、メトリクスの悪化やボトルネックを発見したときも、対処は1つだけではないということを教えてくれます。
参考サイト
本文中で直接言及していない記事・資料について、以下に列挙します。
www.slideshare.net www.slideshare.net www.slideshare.net www.atlassian.com www.testdevlab.com https://www.testingexcellence.com/how-do-we-measure-software-quality-in-agile-projects/www.testingexcellence.com Agile Metrics - What You Need to, Want to, and Can Measure(PDF) www.capriconsulting.co.uk http://www.everydaykanban.com/2016/09/25/flow-efficiency/www.everydaykanban.comまだ読み切れていないものも参考までに・・・。
implementingagile.blogspot.jp www.scaledagileframework.com www.swtestacademy.com techbeacon.com nesma.org