GoogleのテストマネージャーであるJohn Micco氏の、Flakyなテストについてのチュートリアルの内容は、こちらに書き尽くされています。なので、あらためてその復習記事を書くことはないのだけれど、SQLの勉強も兼ねて、要点を絞って振り返っておきます。
nihonbuson.hatenadiary.jp togetter.com
Micco氏のお話の要点は、以下の2つだとわたしは考えています。
- 自動テストが膨大になると、効率よい順番で実行したり、適切に間引いたりすることが重要である。
- シンプルな記録であっても、積み重ねればさまざまな洞察を導くことができる。
この記事では、上述の2つを踏まえてチュートリアルを振り返るとともに、せっかく権限をもらったGoogleさんのログで、少し遊んでみたいと思います。
膨大な自動テストの効率を上げるには
Micco氏の資料*1によると、Googleで継続的に実行されている420万件あり、1日あたりテスト実行が150万回とのこと。
一方、バグが見つかるのはわずか1.23%のテストだけ。膨大なリソースを使うことから、テストを効率的に実行することが求められます。
テスト結果を分析する中で、Micco氏はテストの結果の遷移(transision)に注目。過去にpassしていたテストがある時点でfailに変わるネガティブな遷移は、テストがflaky(あてにならないもの)であることが原因の1つであることがわかりました。flakyなテストについて、スライドでは以下のように述べられています。
- flakyなテストとは、同じコードであるにも関わらず、passになったりfailになったりするテストのこと。
- 420万件のテストのうち、16%が何らかのflakinessをもっている。
- flakyなテストの結果の確認に、開発者の時間が浪費される。そのため開発者は無視しがちだが、その判断が誤っていることもある。
- flakyなテストの(再)実行のために、2~16%の計算リソースを使っている。
- flakyなテストは、進捗を阻害したりリリースを遅らせたりする。
この無駄を減らすことが、自動テスト実行の効率改善の大きな助けになるというのがモチベーションです。
Flakyなテストを見つけるには
チュートリアルで教えてもらったのは、どのようなデータをどう使って分析しているか、ということです。
どんなデータを使う?
実はこの目的に必要なデータベースは、次のシンプルな2つのテーブルです。targetsはテストケース、resultsはテストケースの実行結果と、ざっくり捉えてよさそう。
■targets
| id | INTEGER | REQUIRED | テストのID |
|---|---|---|---|
| target | STRING | REQUIRED | テストケース(のディレクトリパス。これでテストが一意に決まっているようだ) |
| flags | STRING | REQUIRED | テスト環境などの情報をフラグ化したものの組み合わせ |
■results
| target_id | INTEGER | REQUIRED | テストのID | |||
|---|---|---|---|---|---|---|
| changelist | INTEGER | REQUIRED | プログラム変更リストのID | |||
| result | STRING | REQUIRED | 実行結果 | |||
| timestamp | TIMESTAMP | REQUIRED | タイムスタンプ | |||
resultsテーブルの「result」に入るのはテストの結果で、以下のようなものがあります。一部内容を聞いていないものもあります。
- AFFECTED_TARGET
- PASSED: 成功
- SKIPPED
- FAILED_TO_BUILD: コンパイルできずチェックイン不可
- FAILED: 失敗
- INTERNAL_ERROR: テストを開始する前提が満たされなかった。テストインフラの問題
- PENDING: 実行開始できなかった
- FLAKY: 一度のテストの中で、初めは失敗したが、リトライで最終的には成功したもの
- ABORTED_BY_TOOL: 実行時間の閾値15分オーバーによる実行停止
- FORGE_FAILURE
- BUILD_TIMEOUT
- PROHIBITED
- BLACKLISTED
このように結果を細かく分けることで、テストの問題なのか、インフラの問題なのかを切り分けやすくし、開発者とテストインフラチームがお互い時間を浪費しないように工夫しています。
ミッコさんが繰り返し強調しているのは、flakyの分析もさることながら「自動テストの失敗が何に由来しているのか」をきっちり切り分けておいて、たとえば自動テストインフラの問題をdevに投げないような工夫をしている点ですね。#jasst
— Kazu SUZUKI (@kz_suzuki) 2018年3月8日
わたしのチームでもテスト失敗の要因は区別していて、自動テストインフラのどこに改善ポイントがあるのかがわかるようには、一応しています。
プロダクトのバグ起因、自動テストケース起因、テスト環境起因、人の凡ミス、前のテストの影響が残ってしまった、などなど。
Googleとの大きな違いは、この分類を、ほぼ人がやっているということで・・・スケールしないですね。
結局flakyって?
チュートリアルの中では、flakyを2つの意味で使っているように感じました。
1つ目はテスト結果の種類としてのもので、「1回のテスト実行の中で、最初は失敗したが、リトライで成功している」ことを指しています。2つ目はテスト結果の変化の種類としてのもので、「ある時に成功したが、次の実行の際には失敗した」ことを指しています。
でもこの2つって本質的には同じで、結果の変化が1回のテストの中で起こったか、2回のテストの中で起こったかの違いだけなんですね。
よって現時点では単純に、「同じコードで同じ結果を期待しているのに、結果が変わってしまう」ものだと捉えています。
遷移するテストを見つける
チュートリアル最初は、resultsのレコード件数は?みたいなシンプル過ぎる練習クエリを投げていたのですが、遷移するテストを特定するクエリから、以下のようにややこしくなってきます。(MiccoさんのGitHubから引用しています)。
以下読み解いてみますが、解釈が間違っていたり言葉遣いがおかしければご指摘ください。
まず、WITH句で、サブクエリ「result_values」を生成しています。resultsテーブルを並び替えたもので、こんな感じ。*2
| Row | row | target_id | changelist | result |
|---|---|---|---|---|
| 260 | 260 | 1 | 100515424 | AFFECTED_TARGET |
| 261 | 261 | 1 | 100518994 | AFFECTED_TARGET |
| 262 | 262 | 1 | 100519320 | AFFECTED_TARGET |
| 263 | 263 | 1 | 100520152 | AFFECTED_TARGET |
| 264 | 264 | 1 | 100522728 | PASSED |
| 265 | 1 | 2 | 100005012 | AFFECTED_TARGET |
| 266 | 2 | 2 | 100020333 | AFFECTED_TARGET |
PARTITION BYによって、target_idごとにレコードを区分し、changelistでソートしたうえでrow列でナンバリングしています。
「区分」されているため、target_idが変わるとナンバリングが1から再スタートするというところがポイントです。264行目まで増加していたrowが、265で1に戻るのはそういうわけです。
WITHが終わった後のSELECTでは、上で作ったテーブル result_valuesを、自分自身と結合します。結合の条件は、①target_idが一致している ②rowが1個ずれている。
target_idとrowを指定すればレコードは一意に決まりますね。上のテーブルだと、たとえばRow260をRow261と、Row261をRow262と、1行ずらしで順に結合していくことになります。イメージ的には、以下。
| changelist | result | changelist | result |
|---|---|---|---|
| 100515424 | AFFECTED_TARGET | 100518994 | AFFECTED_TARGET |
| 100518994 | AFFECTED_TARGET | 100519320 | AFFECTED_TARGET |
| 100519320 | AFFECTED_TARGET | 100520152 | AFFECTED_TARGET |
| 100520152 | AFFECTED_TARGET | 100522728 | PASSED |
WHERE句で、resultが一致していないものを抽出すると、1番下の行だけが残ります。これって、「あるテストと次のテストで結果が違う」、つまり遷移を表していますね。さらにこれをtarget_idでグルーピングして、遷移が4回以上起きているものを残す。とこういうことをしていたんですね。
まあややこしかったけれど、遷移がよく起きるテストケースを特定することができました。
| Row | target_id | transition_count |
|---|---|---|
| 1 | 84818 | 481 |
| 2 | 29299 | 458 |
| 3 | 70376 | 429 |
| 4 | 71932 | 425 |
| 5 | 92007 | 416 |
遷移の歴史を見抜く
さて次の問題は、「flakyに見えるけれど実はflakyじゃなかった」遷移をどのように見抜くか、ですね。
1つの仮説として、それぞれのテストのflakyさ≒遷移のパターンは、独立しているはずです*3 。逆に、複数のテストが同じような遷移の履歴を示すのであれば、それはテスト以外のものに由来する問題である可能性が高い。Micco氏はそのよ1うな現象の原因として、サブシステムやライブラリの問題を挙げていました。
テスト自体がflakyなわけではないことが明確になれば、テストインフラ側の問題として引き取ることで、開発者の調査の工数を減らせそうです。
まず事前準備として、先ほどのクエリを少し変えて、以下のようなテーブル「target_transitions」を作っておきます。遷移が起こった際のchangelistとtarget_idの組み合わせ表です。
| Row | changelist | target_id |
|---|---|---|
| 1 | 100000001 | 17341 |
| 2 | 100000001 | 28661 |
| 3 | 100000001 | 183752 |
| 4 | 100000001 | 228506 |
| 5 | 100000001 | 259831 |
このテーブルに対し、以下のクエリを投げる。
ざっくりいうと、target_idでグルーピングしたうえで、そこに紐づくchangelistをarray_agg関数で配列にしている。結果がこれです。
| Row | target_id | changelists |
|---|---|---|
| 1 | 424 | 100437692 |
| 100437728 | ||
| 100446646 | ||
| 100452444 | ||
| 1 | 434 | 100031939 |
| 100036158 |
上の表でいうと、(424, [100437692, 100437728, 100446646, 100452444]) みたいになっているってことですね。つまり、「テストケース、遷移歴」のテーブルになっているってことですよ。
この遷移歴が一致するテストケースが多ければ、その遷移・flakyさは、テスト自体と違うところに起因する(可能性が高い)といえるわけですね。
この結果から、遷移する22,760のうち、1,610が遷移歴を共有していることがわかりました。これらはFlakyではないと判断できそうです。
Google先生のデータで遊ぶ
さて、シンプルなデータですが、いろいろできそうな気もしますよね?
少しだけ遊んでみました。
遷移回数を正規化する
上で出た「flaky_tests」テーブルですが、内容は「target_id」(テストケース)と、「transision_count」(遷移回数)です。でもこれだと、実行回数が多いテストと少ないテストを公平に比較できないのでは?と考えるのが自然ですよね。
実行回数はすぐ得られるので、遷移回数/実行回数 で正規化してみましょう。
クエリはこんな感じか・・・?
| Row | target_id | execution_count | transition_count | flake_ratio |
|---|---|---|---|---|
| 1 | 4956 | 29 | 20 | 68.97% |
| 2 | 7764 | 44 | 16 | 36.36% |
| 3 | 8881 | 89 | 22 | 24.72% |
| 4 | 5454 | 21 | 4 | 19.05% |
| 5 | 6792 | 89 | 16 | 17.98% |
| 6 | 434 | 1325 | 186 | 14.04% |
| 7 | 6456 | 1325 | 172 | 12.98% |
| 8 | 6031 | 1254 | 148 | 11.80% |
| 9 | 8769 | 1024 | 112 | 10.94% |
| 10 | 2468 | 1544 | 148 | 09.59% |
| 11 | 4073 | 89 | 8 | 08.99% |
| 12 | 5937 | 45 | 4 | 08.89% |
| 13 | 6902 | 169 | 14 | 08.28% |
| 14 | 7811 | 3071 | 180 | 05.86% |
| 15 | 4901 | 848 | 40 | 04.72% |
| 16 | 1529 | 2629 | 122 | 04.64% |
| 17 | 7091 | 89 | 4 | 04.49% |
| 18 | 7367 | 2806 | 101 | 03.60% |
さっき1位だった434は6位に、2位だった7811は14位に、3位だった6456は7位に。ランキングはそれほど変わらないかな?
Googlerの人たちのホワイトさを調べる
テストと結果のテーブル以外に、「TensorFlowCommits」というコミット履歴のデータがありました。どんな言語でよくfailするのかを、修正対象となったファイルの拡張子から判断したりしています。
チュートリアルで、「誰がよくfailを引き起こしているのか」という分析もあったのでですが、「いや、むしろ何時ごろの修正がfailを引き起こすのか、の方が面白いのでは!?」と。ただ残念ながら、コミット履歴のテーブルの一部が匿名化されており、またテスト結果のテーブルと結合できるキーもないため・・・、一気にスケールダウンし、「googlerは何時にコミットしているのか」を見てみましょう。クエリはたぶんこんな感じ・・・。
この結果をグラフにすると、こう。いきなりExcelですけれど。
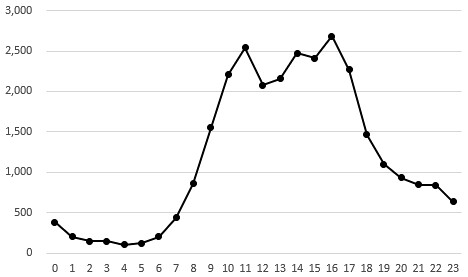
7時ごろに急に立ち上がりはじめ、昼前にピークを迎え、昼休憩をとった後16時ごろにもう一度ピークを見せて、17時ごろから急減。
ただ、意外に、夜中働いていらっしゃる・・・。人間以外のコミットがあったりする、のでしょうか?*4
まとめ
基調講演やチュートリアルで学んだことは、膨大なテストの効率的な実行が必要だけれど、ヒントはシンプルなデータの中からも得られる、ということでした。
何億件というデータはGoogleならではですが、使っている情報も、ロジックも、とてもシンプルと言えるのではないでしょうか。
自動テストはログの蓄積と相性がいいので、自分なりのメトリクスを考えるのは楽しそうですし、効果も見込めそうなので、仕事の中で何か見つけてみたいと思っています。
Miccoさん、ありがとうございました! 謝謝!
*1:The State of Continuous Integration Testing @Google (pdf)
*2:実際は「AFFECTED_TARGET」は除外されている。
*3:実際のところ、20回同じタイミングで遷移するような組み合わせは、わずか2つしかなかったそう。
*4:@nihonbuson さんに、「多拠点開発だからなのでは?」とのご指摘いただきました。なるほどー。