前の記事では、右方向の石置き可否判定を実装しました(Excel関数で)。
今回は、上下左方向の石置き可否判定について考えていきましょう。
「逆方向」の難しさ
右方向さえできれば、左方向も本質的には同じ、簡単に実装できそうです。
しかしここで、Excelの暗黙の前提が効いてきます。Excel関数は基本的に「左から右に」「上から下に」が前提で、その逆を行おうとすると複雑さが増していくのです。
たとえば、カンマで区切られた2つの単語 apple,orange を、左と右に分けることを考えてみましょう。
左側は、カンマの位置をFINDで探して、そのすぐ左までをLEFTで切り取ります。
=LEFT(対象セル,FIND(";",対象セル)-1)
一方右側は、FINDの位置を見つけて対象文字列の長さLENから引いたうえで、RIGHTで切り取ります。ひと手間増えていることがわかりますね。
=RIGHT(対象セル,LEN(対象セル)-FIND(";",対象セル))
返し判定についても同じで、OFFSETやMATCHを逆方向に使うと、一気に複雑になってしまうんですね*1。
ここで少し、発想の転換が必要になります。
盤面を回す
ジョジョ、それは無理矢理方向を変えようとするからだよ。逆に考えるんだ、『方向は固定、盤面を回しちゃえばいいさ』と考えるんだ。
ということで、盤面を時計回りに90度回転させます。たとえばセルC4の座標(4, 3)で、回転後は(3, 5)に移動します。一般化すると、座標(x, y)は(y, 8-x+1)に移動するわけです。これで、右方向への判定を上方向(-90度方向)に適用することができます。
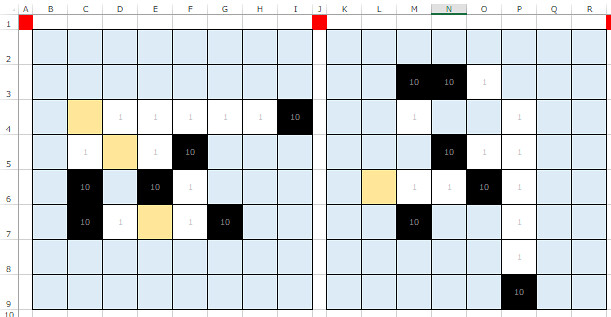
同じように、180度・270度回転させれば、上下左右方向すべてについて、同じロジックで石置き可否判定ができるようになりますね*2。
これをORで結ぶことで、上下左右のいずれかで返せればTRUE、とすることができました*3。
こんなイメージになります。左から4つの盤面がそれぞれ右・上・左・下方向の判定で、一番右の判定は上下左右方向を合わせた判定です。
斜め方向の判定
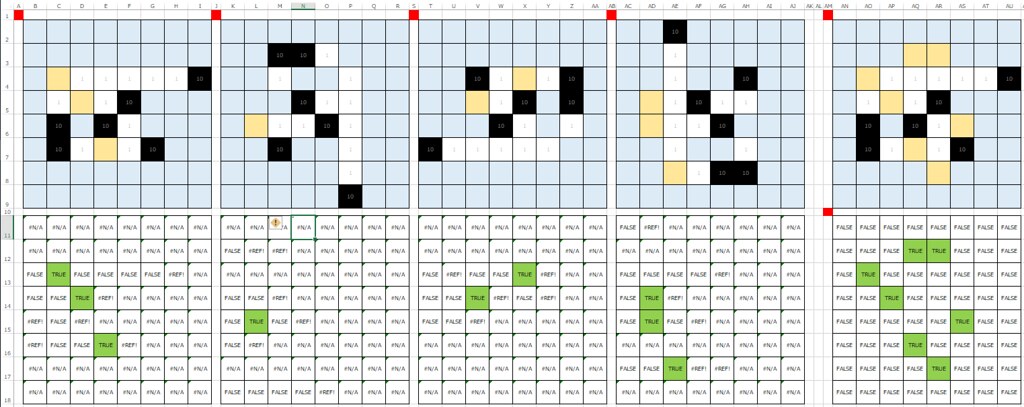
さて、次は斜め方向です。普通に考えて、Excel関数で斜め方向に何らかの処理を行うのは、難しさが一気に増しそうです。
ジョジョ、それは斜めに判定しようとするからだよ。逆に考えるんだ、『盤面を斜めに回しちゃえばいいさ』と考えるんだ。
ただ90度回転とは違い、斜め回転には少し工夫が入ります。結論を言うと、盤面を分割する必要があります。百聞は一見にしかず、要は、こう。
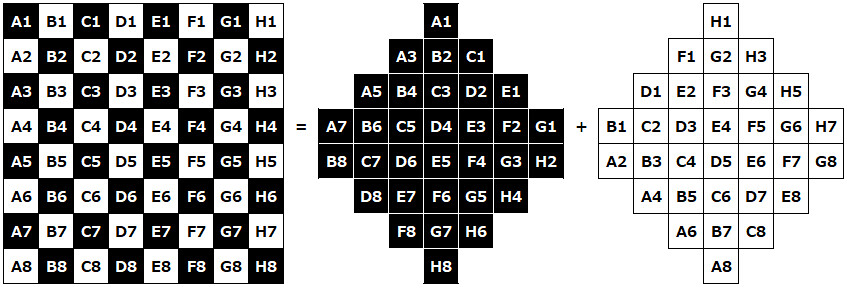
この分割後の盤面について、最初のロジックで判定すればいいわけです。シンプルな解法ですよね。
力尽きる
単に石を置けるかどうかだけでこんなに苦労してしまいました。もしかして、Excelワークシート関数で実装するという判断は誤っていたのでしょうか?
Excelワークシート関数だと、「石を置けるか」の判定まではできても、実際に返すことができない。
— Kazu SUZUKI (@kz_suzuki) 2018年7月7日
同じ ●○● でも、左を最後に置いたなら真ん中の○は返るし、真ん中を最後に置いたなら○は返らない。だからどの石を「最後に」置いたかの情報が必要で、Excelワークシートではそれが難しいかも…。
あとはExcel職人の皆さんにお任せしたいと思います!
それでは良い週末を!

")