はじめに
テストケースの数が多くなってくると、それらをグルーピングする必要が生じます。
たとえばExcelテスト管理パラダイムであれば、ワークシートに「大分類」「中分類」「小分類」という列を設けて、階層構造を表現することが可能ではあります*1。
では、テスト管理ツールではどのようなグルーピングが理想的でしょうか?
なお本記事では、テストケースを管理する目的を以下とします。
一貫したルールに沿ってテストケースを体系だてることで、テストセットの全体像の把握や、テストケースの取捨選択が効率的に行えること。
結論
開発項目をツリーで表現してテストケースを分類したうえで、テストタイプやテスト目的でタグ付けして管理すると、見通しがいいんじゃないかね。
本文の前に
関連記事
この記事を書くキッカケとなったのは、きんぢさんの以下の記事です。 qiita.com
またこの話の前提として、テスト管理ツールにおけるテストケース管理について、以下を読んでいただけると。 www.kzsuzuki.com
言葉の定義
テストスイート(test suite)は、JSTQBでは以下のように定義されています。
特定のテストランで実行されるテストスクリプト、またはテスト手順のセット。
テストケーススイート(test case suite)、テストセット(test set)もその同義語とされています。
定義上「テストケース」という言葉すら出てこず、ちょっと不便なので、この記事では
テストセット: 特定のテストランで実行されるテストケースの集合。
という意味で使います。で、ついでに以下を定義しておきます。
フルテストセット: 定義されたすべてのテストケースの集合。
ツリー構造とタグ付け
多くのテスト管理ツールでは、テストケースの管理方法として、「ツリー構造」と「タグ付け」*2をサポートしています*3。
ツリー構造による管理
考え方
OSのファイル管理におけるディレクトリのように、フォルダを分けてテストケースを管理する方法です。フォルダには、テストケースだけでなく、別のフォルダを入れ子にすることもできます。
あるテストケース・フォルダは、1つのフォルダにしか所属することができないため、ツリー構造が形成されます。
長所
結局ヒトは、ツリー構造・階層構造にわかりやすさを見出すものです。扱う対象が大きいほど、divide and conquerってなもんで分割していく。それはツリー構造になっていくはずです。思えば上述のExcelテスト管理パラダイムにおける「大分類」「中分類」「小分類」も、ツリー構造によるグルーピングですね。
ツリーがきれいにできていれば、「フィーチャにA関するテストはこのディレクトリより下に全部集まっている」ということが一目でわかるようになります。
短所
あるテストケースが1つのフォルダにしか所属できないという性質から、融通がききづらいのが短所。ツリーを構成する際には、MECEと一貫性に配慮が必要です。
MECE(もれなくダブりなく、Mutually Exclusive, Collectively Exhaustive)から考えてみましょう。
CEの方は、万能の「その他」でしのぐ*4としても、あるテストケースが1つのフォルダにしか所属できない以上、フォルダ同士はMEでなくてはなりません。
Exclusiveでない、つまり「ダブりあり」だと、そのダブった属性を持つテストケースをどちらに配置すればいいかわかりません。「2021年度」フォルダの下に、「第3四半期」と「下半期」というサブフォルダが共存してはいけないわけです。
また、分類の軸に一貫性がないと、混乱をきたします。
極端な例ですが、「入力バリデーションチェック」と「リグレッションテスト」みたいなフォルダが共存してしまうと、「値のバリデーションチェックを行うリグレッションテストはどっちに入れればいいのか」ということになってしまいます。
タグ付けによる管理
考え方
所属先を1つしか指定できないツリー構造に対し、タグ管理では1つの対象に複数のタグを付与することができます。たとえばFirefoxのブックマークやEvernoteのノートは、タグで管理することができます。
長所
ツリー構造のような、「親は一人だけ」の制約がないことが最大のメリットです。
1つのテストケースに対し複数のタグを与え、それぞれのタグで検索することができます。これによってたとえば、「性能テスト」といったカットでグルーピングができるわけです。
短所
MECEを自然と意識させるツリー構造と比べて、タグは自由に作れます。この自由さは、無秩序と表裏一体です。そして一貫性のないタグの増殖は、タグ付けの煩雑さと検索性の低下につながります。
タグ付けによる管理においては、タグの作成ルールが必要です。
おすすめプラクティス
ここからは完全に私見です(そしてこれまでも完全に私見です*5)。
ツリー構造に合うのは、テスト対象となる開発項目、またはそれをテストのために整理しなおしたテストアイテムだと考えています。DevチームとQAチームがゆるやかにでも分かれている場合でも、両チームの意識を合わせやすいです。開発項目というのは、テスト以前に、ある程度ツリー構造化されていることも多いからです。
ただし、階層をあまり深くし過ぎると逆に管理しづらくなるので、「どこまでを階層構造で表現し、どこからをテストケース名で表現するか」というポリシーは決めておいた方がいいでしょう。
一方タグ付けは、テスト目的やテストタイプによるグルーピングに用いるとよいでしょう。
ツリーとタグの組み合わせによって、開発項目の階層構造を横断する形で、目的に応じたテストをフィルタすることができます*6。
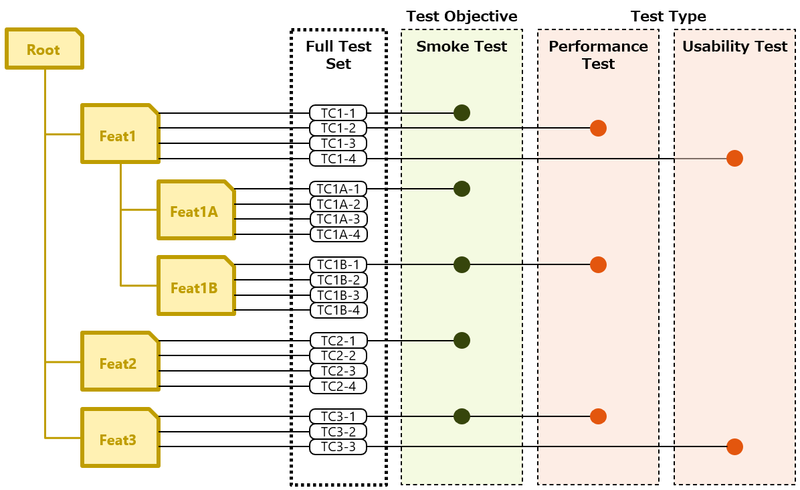
最初の絵は、これを図示したものです。
Full Test Setには、定義されたすべてのテストケースが所属しています。これは開発項目のツリー構造に関連づいています。
一部のテストケースは、タグ(●で表現)が付与されており、たとえば「スモークテスト」を簡単に特定することができるというわけです。
ただし・・・
注意点が2つあります。
ツールの性能も大事
グルーピングは、テストケースが多くなればなるほど重要になります。
一方で、テストケースが多くなるほど影響を受けるのが、テスト管理ツールの性能です。
テストケースのツリー間移動、タグの付け外し、そして検索とフィルタ。いくら論理的にはきれいな構造を作ったとしても、これらの機能がモタつくようでは、せっかくの構造も使い物になりません。
グルーピングの先にあるもの
テストセットの中から、テストケースをグルーピングする方法について述べてきました。
一方、テストケース同士、テストセット同士の関連を記述する方法については、何も述べていません。テスト対象が大きくなると、この関連の表現がより重要になってくると考えられます。
おわりに
テスト管理ツールを使って、テストケースをグルーピングする方法について書きました。
ところで、前回の記事を書いたあと、このようなツイートをお見かけしました。
テスト管理ツールはテスト実行者を型にはめて縛るものだと思って若干どこか敬遠してた時期が私にはあったけどそれはツールのこと全然わかってないだけだった
— Harue Takeda (@haruetakeda) 2021年12月30日
たしかに、「テスト実行者を型にはめて縛る」という印象はよくわかります。これって、チケット管理ツールを導入した際にも感じたことではないでしょうか?
ただ使っていくうちに、わかってきます。
チケット管理ツールもテスト管理ツールもただの「箱」であって、いろいろできるけど、結局のところ「運用ルールを自分たちで作らないと、グチャグチャになる」ものです。グッドプラクティス的なものは出てくるでしょうけれど、どこの現場の事情・文化にも合う完璧なプラクティス*7ってのは難しいんじゃないかなと思います。

*1:なおこのプラクティスは、にしさんにより「固定3レイヤー法」と命名されています。「考える抽象度が固定されてしまう」との注釈付きで。
Excel大中小項目法に、固定3レイヤー法という名前を付けました。CPM法と同様に、私が提案したのではなく、私が「発見」した方法です。 先生が仰っておられるように、考える抽象度そのものをデザインしながら進めるのがVSTePです、先生。考える抽象度が固定されてしまうのが、固定レイヤー法です。
*2:タグは「ラベル」と呼ばれることもあります。
*3:Evernoteは、タグ自体をツリー構造にできる。もしかしたらこれが最強なのか?
*4:「その他」は整理されていないゴミの集積所になるリスクがあるので注意。
*5:いせりさんがツイートされたよう100万オーダのテストケースという規模は、わたしは未経験です。想像つかない・・・。
テスト管理ツール、百万件とかの規模になるとツリー構造、タグ付け構造、どちらかでなく、両方サポートが望ましい。スコープを限定するパッケージ構造、ツリー構造、タグ付けによるセレクション全部いる。テストケースとテスト実装成果物を別々の観点でグルーピングする機能も必須
*6:完全に余談ですが、わたしのEvernoteは読んだ本のメモが多いので、「IT技術」「科学」「語学」といった「分野」によるツリー構造と、本に対する評価タグで管理しています。これによって、「2021年に読んだ科学関連の本で、★が4つ以上のもの」といった検索できるようになっています。ツリー×タグは強い。
*7:「銀の弾丸はない」は意地でも言わない。







")

")





