最近ポエムしか書いていないのですが、今日も元気にポエム as a excuse(言い訳としてのポエム)です。
「テスト自動化の目的は工数削減!」というのは筋悪な思考と言われがちですが、それをあえてお絵描きしてみました。
工数削減だけが嬉しさ?
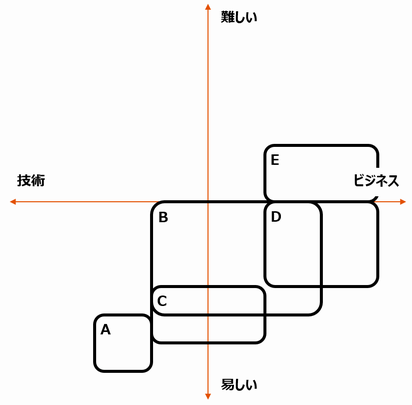
これまで、300時間かけて、AとBの手動リグレッションテストを行っていたとします(左下。数字は適当です)。このうち200時間分に相当するBを自動化することにしました。結果として、Bの実行にかかる工数が20時間になったとします(右下)*1。


Cの180時間が、自動化によって削減できた工数です。
全体では300時間(A+B+C)が120時間(A+B)になり、60%の工数削減を実現した!と言えなくもありません。ただこれだけだと、実行が手動から自動になって、所要工数が小さくなったことだけが嬉しさに見えますね。
できなかったことができるようになるのも嬉しさ
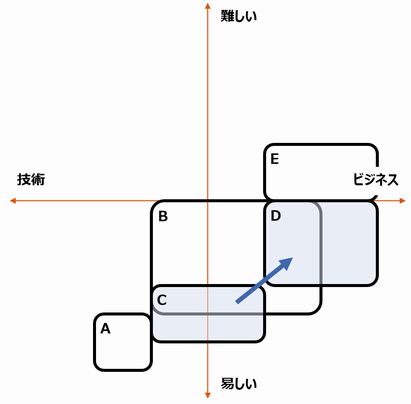
自動化のご利益である「同じことを繰り返し実行できる」ことを活かすことができれば、こんな絵になります。

この右側(DとE)は、「やりかったけど、できていなかった」テストです。手動でやると1,500時間(D+E)もかかるので手が出せていなかったけれど、自動化により150時間(D)に短縮されることで実行可能になったということを表しています。
たとえば以下のようなものですね。
- ある機種ではテストできていたけど、それ以外の機種ではテストできていなかった。
- 連携する3rd party製品の特定のバージョンでしかシステムテストできていなかった。
- 実行できるテストパラメタの組み合わせが、少数に限られていた。
- リグレッションテストの頻度が低すぎた。
もちろん、リスクを考慮したうえで不要と判断したテストであれば、自動化したからといって急に実行要になるわけではありません。一方で、本来はやるべきなんだけど、手動だとスケジュール的にどーーーしても無理。と涙をのんで落としているテストもあるでしょう。
この「やりかったけど、できていなかった」範囲を自動テストでカバーすることで、テストのカバレッジを上げ、バグを見つける可能性を高めることができます。工数だけじゃなく、品質に寄与しているわけです。
「自動テストの効果」ってどれ?
この絵をよく見ると、テストを増やすことで150時間(D)が「余分に」追加されています。自動化で削減したはずの180時間(C)のほとんどを食いつぶしていますね。自動テストの実装・メンテのコストを考えると、節約分を逆転することもあるかもしれません。つまり、「テストの工数は全然減ってない」と見なすこともできるわけです。
自動テストの効果は、見る人によって変わります。
今回のような単純なケースでも、以下3つの見方があるでしょう。
遠くから見ている人
「自動化したのに、テストにかかる時間は300時間(A+B+C)が270時間(A+B+D)になっただけで、10%の工数削減でしかない。どういうことだ!?」
もともと行っていたテストに注目する人
「300時間(A+B+C)が120時間(A+B)になったのだから、60%の工数削減だな。まあ、いいか。」
テスト実行全体に注目する人
「本来やるべきテストを手動で行うと1,800時間(A+B+C+D+E)かかっていたはずで、これが270時間(A+B+D)になったのだから、85%の工数削減である。しかもテストカバレッジが高まり、拾えるバグも増え、品質リスクを下げている。ヨシ!」
ちょっと極端ですが、この辺の意識が合っていないと、「自動化って効果ないね」となりかねません。
まとめ
単純な例で、自動化の効果の見え方について述べました。
わかりやすいメトリクスとして「削減工数」を使うことは悪いとは思わないのですが、「何を測っているのか」「それは実態を表現できているのか」には注意を払わないないとマズいですよね。
また工数削減を「一つの目標」にするのもいいのですが、「唯一の」「最終目標」にするとズレちゃうかなと。テスト工数ってプロダクトの価値とあまり関係のない指標なので。
よく言われることですが、削減できた工数の一部をより良いテストの実現のための時間に充て、品質につなげることで、自動テストのご利益を最大限享受できるといいですね。
 "Automata" by the_junes is licensed under CC BY-NC 2.0
"Automata" by the_junes is licensed under CC BY-NC 2.0![]()
![]()
![]()
*1:自動化しても人の作業はゼロにはならないことを意味しています。







")