Twitterで、「組み合わせテストに分類されるテスト技法はどれか」という話が流れていました。
デシジョンテーブル、原因結果グラフ、原因流れ図といった、いわゆる「有則」のテスト技法でも命題の真偽の組み合わせを考えますが、これは組み合わせテストに含まれるかそうでないのか、というものです。
わたし自身以前、(無則の)組み合わせテストを人に説明するときに少しモヤモヤしたので、自分の意見を整理しておきます。
TL;DR *1
- 自分の中で整合性が取れていて、かつ世の中の一般的な理解から大きくハズレていなければいい*2。
- 用語が有名なのに指す範囲が人しだいというのは議論の妨げになるので、立場を明確にしておくのがベター。
- combinatorial testing はテクニカルタームとして、無則の組み合わせテストを指すとすると都合がいい。
- 有則のテストの中にも「組み合わせのテスト」はある、と補足しておくといい。
combinatorial とは
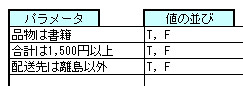
とりあえずJSTQBの用語集で「組み合わせテスト」を検索すると、以下の結果が出ます*3。
組み合わせテスト(combinatorial testing)
ブラックボックステスト設計技法の一つ。複数のパラメータの値を特定の組み合わせで実行するためのテストケースを設計する。
そもそも、combinatorial というのがふだん見慣れない単語ではないでしょうか。combinational とどう違うのか。
こんなときにに役に立つのが「vs検索」ですね。
たとえば、ともに「継続」のニュアンスがある continuous と continual の違いが知りたければ、「continuous vs continual」で検索して、信頼できそうなサイトを読んでみることでそれなりに理解できることが多い。下のサイトを見ると、continuousは「頻度は高いが断続的である」ようなニュアンスがあることがわかります。
en.oxforddictionaries.com
という成功体験を胸に、調べてみましょう。
As adjectives the difference between combinatorial and combinational is that
combinatorial is of, pertaining to, or involving combinations
while
combinational is of or pertaining to (a) combination.
明確な違いが、「combinations」なのか、「a combination」なのか、だけ・・・? なんかもっとこう・・・。
以下は数学の文脈になってしまいますが、また名詞と形容詞の比較なので少し奇妙ですが、
In context|mathematics|lang=en terms the difference between combination and combinatorial is that combination is (mathematics) one or more elements selected from a set without regard to the order of selection while combinatorial is (mathematics) of or pertaining to the combination and arrangement of elements in sets.
これもなかなか難しい。
ただここで「数学」というキーワードから、「順列」「組み合わせ」と関係あるのでは?と思っていろいろググって見ると、「組み合わせ数学」(combinatorics)という分野があるのですね。組み合わせ最適化(combinatorial optimization)もこの分野に含まれていることがわかります。
組合せ数学(くみあわせすうがく、combinatorics)や組合せ論(くみあわせろん)とは、特定の条件を満たす(普通は有限の)対象からなる集まりを研究する数学の分野。特に問題とされることとして、集合に入っている対象を数えたり(数え上げ的組合せ論)、いつ条件が満たされるのかを判定し、その条件を満たしている対象を構成したり解析したり(組合せデザインやマトロイド理論)、「最大」「最小」「最適」な対象をみつけたり(極値組合せ論や組合せ最適化)、それらの対象が持ちうる代数的構造をみつけたり(代数的組合せ論)することが挙げられる。
これで、最初の「combinations」「a combination」の意味が何となくみえてきます(個人の感想です)。
a combination は、「組み合わせの行為・結果」です。たとえばA~Eまでのチームがあったとして、最初の試合が「チームA vs チームC」であれば、「AとC」というのは a combination。日本語の「組み合わせ」にほぼ合致しそうです。combinational はそれを形容詞にしたもの。
combinatorial は、結果自体ではなく、a combination に至るまでの組み合わせの「基準」や「方法」を含意しているように感じます。たとえば先の5チームでリーグ戦を行うとき、「総当たり」などの組み合わせ導出のアルゴリズムを考えることが combinatorial な議論であり、その結果導出される複数の組み合わせ10試合が combinations になるわけです。
組み合わせテストに含まれる技法は?
やっと話が戻ってきます。
Twitterの議論のポイントは、「組み合わせテストは、無則の組み合わせのみを指すのか、有則の組み合わせも指すのか」というものでした。
ISTQBでの扱い
用語集では以下のように定義されています。
ブラックボックステスト設計技法の一つ。複数のパラメータの値を特定の組み合わせで実行するためのテストケースを設計する。
これを読むと、無則に限るものではないと読めますね。
またTechnical Analystシラバスでは以下のように記載されています。
Combinatorial testing is used when testing software with several parameters, each one with several values, which gives rise to more combinations than are feasible to test in the time allowed. The parameters must be independent and compatible in the sense that any option for any factor can be combined with any option for any other factor. Classification trees allow for some combinations to be excluded, if certain options are incompatible. This does not assume that the combined factors won’t affect each other; they very well might, but should affect each other in acceptable ways.
組み合わせテストは、複数の値を持つ複数のパラメータを含むソフトウェアをテストする場合で、組み合わせ数が、許容される時間内にテスト可能な数よりも多く存在するときに使用する。どのようなパラメータのどのようなオプションでも、他のどのようなパラメータのどのようなオプションと組み合わせられるという意味で、パラメータ間に依存関係はなく、両立させるべきである。
「パラメタは独立しており、各値が自由に組み合わせられる」という記述は、無則のテストを想起させますね。用語集より一歩踏み込んでいます。
またそもそもTAのシラバスは、章構成としても、「3.2.3 デシジョンテーブル」「3.2.4 原因結果グラフ法」とは別に「3.2.6 組み合わせテスト技法」となっており、有則のテストを組み合わせテストの外に位置づけているようにも読めます。
ところが。
実は先日公開のJSTQB FLシラバス 2018のp.56「4.2.3 デシジョンテーブルテスト」は冒頭で「組み合わせテスト技法は・・組み合わせテストのアプローチの1つとしてデシジョンテーブルテストがある。」と書かれています。原文のISTQBでは"Combinatorial test techniques"、後者は"such testing"です。
— Keizo Tatsumi (@KeizoTatsumi) 2019年3月30日
この辰巳さんのご指摘*4の箇所を引用すると、以下です。
Combinatorial test techniques are useful for testing the implementation of system requirements that specify how different combinations of conditions result in different outcomes. One approach to such testing is decision table testing.
確かに combinatorial test techniques という言葉が出てきます。このシラバス内で、combinatorial という単語が出てくるのはこの箇所だけのようです。
ISTQBの既存のシラバス・用語集での立ち位置を考えると、デシジョンテーブルを combinatorial testing の一つとして扱うのは確かに奇妙、と思います。
『ソフトウェアテスト技法ドリル』での扱い
わたしのバイブルでもある『ソフトウェアテスト技法ドリル』を確認してみましょう。

- 作者: 秋山浩一
- 出版社/メーカー: 日科技連出版社
- 発売日: 2010/10/01
- メディア: 単行本
- 購入: 7人 クリック: 153回
- この商品を含むブログ (19件) を見る
「本書の読み方」の表1によると、以下のように分類されています。
論理組合せテスト
ドメイン分析テスト
デシジョンテーブル
原因結果グラフ
CFD法無則組合せテスト
HAYST法
スライド法
ペアワイズ
前者はいわゆる「有則」に相当しますので、有則・無則の双方に、「組み合わせテスト」という言葉を当てたうえで、「論理の」「無則の」という言葉で区別しています。
まとめ
有則の組み合わせにせよ無則の組み合わせにせよ、「組み合わせの方法を与える」という意味では、combinatorial とはいえそうです。
一方、コードカバレッジ基準、たとえばMC/DC(改良条件判定カバレッジ)だって真偽値の「組み合わせ方」ではあり、それらを全部 combinatorial testing と呼んでしまうと、名前をつける意味すらなくなってしまいます。
ということで再掲ですが、以下のように考えます。
- 自分の中で整合性が取れていて、かつ世の中の一般的な理解から大きくハズレていなければいい。
- 用語が有名なのに指す範囲が人しだいというのは議論の妨げになるので、立場を明確にしておくのがベター。
- combinatorial testing はテクニカルタームとして、無則の組み合わせテストを指すとすると都合がいい。
- 有則のテストの中にも「組み合わせのテスト」はある、と補足しておくといい。
次回は、「組み合わせ」と「組合せ」の違いについて検討していきたいと思います。より深刻だよ。
「組み合わせ」の送り方の組み合わせは、「組」「組み」と「合」「合せ」「合わせ」で計6種類もあるのか。一見独立にも思えるが「組合」は別の意味になってしまうので禁則だし、むずかしいぞ。 https://t.co/U126szfs3M
— Kazu SUZUKI (@kz_suzuki) April 3, 2019
*1:1回書いてみたかっただけ。「too long; didn't read」の略なんですね。en.wikipedia.org
*2:居駒さんからのご指摘を踏まえて、4/6に書き直しました。
直交しているので、「組み合わせテストではない有則のテスト」は当然あります。なので、『有則のテストも「組み合わせのテスト」ではある』ではなく、『有則のテストも「組み合わせのテスト」のことがある』が正しい記述だと私は思います。 有則のテストも「組み合わせのテスト」ではあると補足しておくといい
元の文章は以下です。
*3:2019年4月3日時点。
*4:なお一連の辰巳さんのツイートは、一通り読んでおくべきですね・・・、。